随着人工智能在安防、泛安防等领域迅速落地和普及,各类图像视觉类AI算法落地的精度和实际效果在提升,获得了更深广的业务价值,如安防领域的人脸布控、人车视频结构化等,泛安防的社区园区通行,新零售的VIP客户识别等,都是AI技术商业化的典型场景。
同时,视觉类AI算法的深度学习计算,也逐步从云端部署扩展到边缘部署。边缘的设备比云端多1-2个数量级,业内对边缘AI计算硬件的需求快速升温,大家呼唤高算力、低功耗、接口丰富的芯片和模组方案的出现,来替代原来的CPU、GPU方案。而比特大陆算丰AI计算模组SM5,定位为国内最强算力的AI边缘计算模组,成为让人眼前一亮的选择。它基于AI专用芯片(ASIC),在算力上突破了17 TOPS量级,达到了惊人的16到30路的潜在视频计算分析能力。难得的是,在高算力同时保持了相对低功耗、被动式无风扇散热、接口丰富等优点。可以说是国内AI边缘计算模组中的领军产品,吸引了诸多安防、泛安防客户的眼球。不仅如此,作为国产厂商的纯自主研发产品,也为特种行业领域提供了新的选择。比特大陆算丰AI计算模组SM5实测效果如何,我们一一验证。
小体积 大集成
从外形来看,比特大陆算丰AI计算模组SM5 (Sophon SM5)极为小巧,尺寸仅为普通信用卡大小,算连接器为87×65×8mm,不算连接器为87×65×3mm。底座为144针高密接口,供客户开发底板,嵌入到各类设备之中。该模组采用宽温设计,散热方案可以选配比特大陆的被动或主动散热方案,客户也可自行设计。可适应-20℃到+55℃的工作环境,有效降低恶劣环境对模组的影响,从而支持系统的持续运作。模组满足极端环境的作业需求,可应用在室外半封闭场所。比特大陆该模组采用双模驱动,内置12G内存,既可作为AI计算的从设备(PCIE mode),也可作为主设备独立运行(SOC mode),可支持FP32(2.2T)高精度的计算,INT8计算经过自动化编译校准的精度损失可小于<0.5%。另外,该模组接口丰富,具有10+接口类型。支持PCIE EP/ PCIE RC / Ethernet / RS485/ RS232/ GPIO /SDIO / PWM等接口。扩展性强,可扩展USB/SATA/HDMI等,可扩展SATA存储,可扩展4G/5G/wifi等。总的来说,比特大陆算丰AI计算模组SM5体积小、低功耗、双网口、接口丰富,工作宽温,高集成度,可以方便的被集成在各类边缘计算设备、嵌入式设备、自动化机器之中。


SM5模组底面图
自主研发芯片 算力强大
比特大陆算丰AI芯片是其纯自主研发产品,具备200+专利申请。比特大陆算丰AI计算模组SM5基于比特大陆算丰AI芯片BM1684,为比特大陆的第三代云端AI芯片,属于历代规格最高,算力最强,同时3代的产品研发迭代,在客户持续使用反馈中,产品的成熟度得到了诸多行业客户的打磨和提升,进入了成熟阶段。判断芯片的主要标准即为算力、功耗。a&s实测该模组的算力达到17.6TOPS,在Winograd卷积加速下最高可达35.2TOPS。ARM CPU下算力最强,8核A53主频2.3GHz,边缘AI芯片内最强,可灵活开发应用。实测中,该模组Resnet50的测试吞吐可达到1000 张/秒以上。安防的应用要从整体的视觉应用层面,端到端的来看性能指标。典型的安防视觉AI计算过程包含从外部视频流/图片流进入模组,网口取数据,视频/图片解码,视频前后处理,AI计算,同时CPU参与部分计算,最终输出等。从该模组的测试结果看,其最高支持32路30FPS的1080P解码,支持H264/H265格式,支持视频编码最高960 FPS;具备硬加速的图像前后处理能力(Crop/Resize/色域变换),有效提升应用性能。常见Resnet50等神经网络运行典型功耗12W以内,16路视频流全流程分析典型功耗为16W。在满载情况下,典型功耗也不到20W功耗。可以在无风扇的被动散热方案下,持续有效的长期运行。
业界比对测试 效果良好
除了从典型安防视觉AI计算过程衡量模组的算力和整体性能,a&s将英伟达TX2、华为ATLS200等模组方案与比特大陆算丰AI计算模组SM5进行横向对比测试,同类对比技术规格来看,算丰SM5的技术指标在CPU、AI算力、视频解码、内存、以太网端口等等都具备较大的优势,可以说说得上是业内超强算力。从测评数据中可以看出以下几点:在AI算力方面,与TX2 、ATLS200相比具有明显优势;在视频解码上,是TX2 、ATLS200的两倍;内存为12GB,是TX2 、ATLS200的1.5倍;以太网端口是2个,而TX2 、ATLS200均只有1个;从测评数据来看,比特大陆算丰AI计算模组SM5的优势相对英伟达TX2、华为ATLS200优势明显,虽然功耗相对较大,但与其余对比项相结合后,性价比仍然最高。
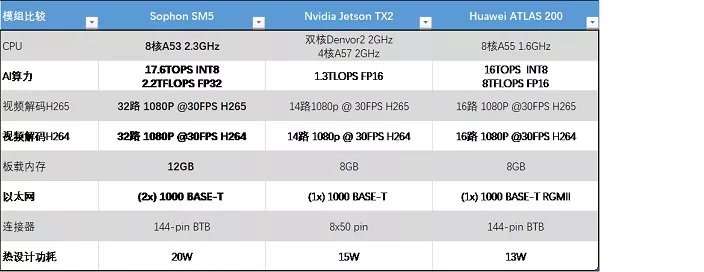
测试数据来源为比特大陆实验室
算力和AI分析路数从实际应用和神经网络benchmark两个角度测试比特大陆算丰AI计算模组SM5。该模组在安防的实际应用主要指标为可接入的视频路数和视频分析应用能力。在安装1块SM5模组搭载的测试底板后,引出来网络、电源等接口,将视频流服务器发过来视频进行多路处理和分析,并将检测人脸框打在视频流上编码输出显示。在16路1080p视频流输入的情况下,每路视频实时画面达到10人脸以上,单个SM5模组可以实现完全实时的满帧的处理人脸检测和跟踪。

上图是16路1080P的满帧处理情况,仅仅为初步部署,并未进行优化。用户可以自行开发算法软件,并进行适度优化,完全有可能实现单个模组超过16路甚至30路视频流的人脸检测分析,或者视频结构化的业务分析能力,可以说在应用端到端的算力非常强大。SM5模组的实际应用算力实测非常强,相应的神经网络模型速度肯定也很快。a&s将SM5模组、Nvidia TX2模组,以及Huawei ATLAS 200模组做了性能实测比对,在几种典型的神经网络分类模型测试中,吞吐数据如下表:
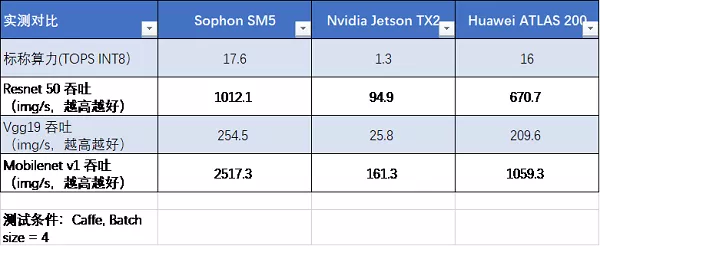
测试数据来源为比特大陆实验室从实测结果来看,在性能上,SM5相比TX2有十倍级别的性能优势。相比ATLAS 200,虽然理论峰值标称算力SM5和ATLAS200很接近(17.6T vs 16T),但是从实测来看,SM5的性能倍数在最典型Resnet 50上有1.5倍的优势,在Mobilenet上有2.38倍的优势!这说明,标称算力和实际获得的算力具有一定的差别。算丰SM5具有较高的有效计算利用率。
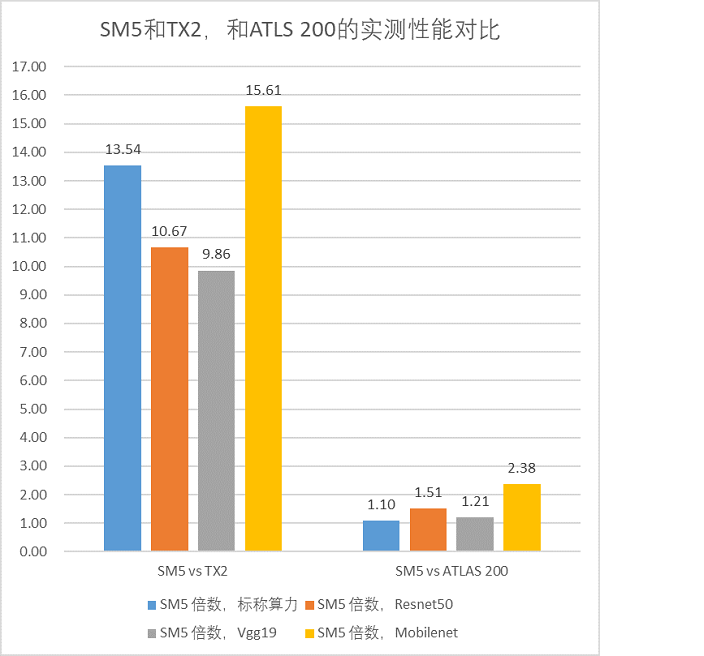
总的来看,无论是实际应用的性能,还是神经网络模型的速度吞吐,SM5模组都是很强大的,和业内其他产品相比也有较大的优势。
工具链完备,易用度高
对于开发者而言,都希望开发简单易用,特别是从CPU,GPU等的以前的模型和算法,能够比较轻易的转到新的AI硬件上来。而比特大陆的算丰AI芯片的多种产品(板卡、模组、盒子),保持统一的工具链和系统软件。其中工具链完备,开发友好:包括底层驱动环境、编译器、推理部署工具等一系列软件工具;支持Caffe、Tensorflow、PyTorch、PaddlePaddle等深度学习框架,离线编译和校准工具易用;完备的性能监控工具、神经网络运行库、视频编解码库、图像编解码库、图像处理库;可提供算法测试用例,包括人脸检测、物体检测等。
可应用场景广泛
比特大陆算丰AI计算模组SM5的定位是被集成,所以应用场景是多种多样的,包括了AI边缘计算服务器,智能NVR,AI边缘计算盒,机器人,大中型无人机等等。模组的主要功能就是进行视觉AI的计算,能够为传统产品附加AI功能,支持人脸检测与识别、面部表情分析、物体检测与识别、车牌识别、声纹识别等,可应用于人脸识别、自动驾驶、城市大脑、智能安防、智能医疗等人工智能场景,应用领域广泛。
可以说,BM1684作为比特大陆多年AI技术积累和沉淀的第三代AI芯片,构建的AI模组具有鲜明的特点,优势诸多。
产品特色
1、超强算力、低功耗、自主芯片。2、易被集成、低功耗、双网口、接口多。3、体积小,被动散热,易集成。4、双模驱动,接口丰富,扩展性强。
5、工具链完备,易用度高。
点评
这是一款算力超强的AI计算模组,从应用性能和神经网络实测来看,算力非常强大,可以说是目前阶段业内最强。同时具备视频解码、后处理、CPU强大能力,有可能在视觉AI全流程起到完美的加速效果。同时还保持了易集成,低功耗等特点,如此强大的边缘计算模组,确实是业内的强算力模组的最佳选择之一。预计算丰SM5模组会在安防、智慧城市、机器人、新零售等领域,加速AI在业务中的普及和落地。
主要规格参数
| 算力 | 17.6T算力,32路解码,16路-30路AI分析 |
| 芯片 | 比特大陆算丰品牌,自主研发12nm芯片BM1684,成熟第三代 |
| 功耗 | <16瓦,被动散热,-20—55℃ (高温定制设计) |
| 双模驱动 | PCIE、SoC双模,FP32、INT8精度双模 |
| 集成度 | 信用卡大小,12G内存,10+接口类型 |
| 工具链 | Caffe、Tensorflow、PyTorch、MXnet,Paddle Paddle |
(本次测试为a&s与厂家共同内部测试,产品后续发布时间敬请期待!)






评论前必须登录!
立即登录 注册